【粵語講呢啲】探討AI在中文範疇上的「思路」
梁振輝 香港資深出版人
印象中,在兩三年前,AI(人工智能/人工智慧)這個資訊科技名詞,悄悄地打進了世人的心。
2025年1月20日,國產DeepSeek(深度求索)發布了DeepSeek-R1模型;據稱效能可媲美、甚至超越OpenAI和Google等美國科技巨頭的AI模型,且開發成本大幅降低。一時間,性價比高的DeepSeek除燃起全球對AI的熱情,還掀動新一波市場競賽。
熱情歸熱情,近期確有不少人提出了如以下般引起「恐慌性」的課題:
AI的湧現教我重新思考人生?
AI將搶走我的飯碗?
不久的將來,若然不懂AI將被淘汰?
AI不日會否天下無敵?
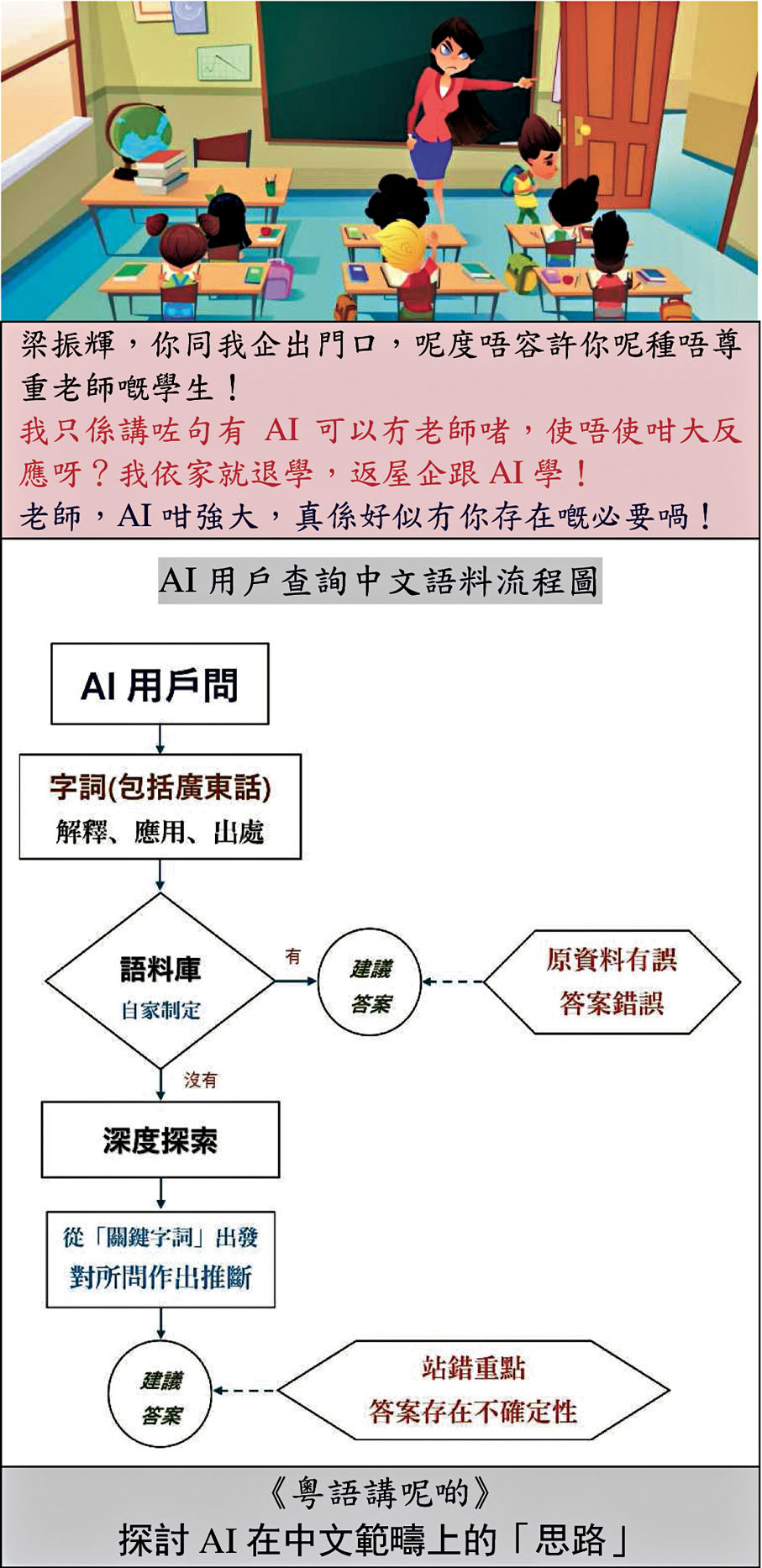
現代人要是有需要查詢,為了便捷,一般訴諸網上尋索。事實告訴我們,部分資料因「人皆可發表」而存在不確定性;換言之,不盡可靠。
各大中外具規模的AI模型會在各範疇內建立自家龐大的資料庫。就有規範性的書面語與普通話而言,筆者深信由內地開發的AI可稱得上充分備至,且沒多大爭議性。然而,對於沒有正式規範的粵語——口耳相傳以致以訛傳訛——成品出現謬誤、曲解甚至無解在所難免。粵語數據來源主要來自公開的粵語文本資源,如社交媒體、新聞、經商業授權的方言語料等。據筆者的了解,社交媒體的信息可靠性存疑。試問在具有這種缺陷特性的粵語語料庫的基礎上,如何保證成品不出現狀況呢?對「直接取用」的用戶來說,不是「間接承擔」着一定的風險嗎?
AI最強的賣點是當遇上語料庫未有覆蓋的信息時,它會運用一種「深度探索」的思維推敲用戶的問題,務求給出合理的回答;真正體現了老子的「無中生有」——原指萬有生於虛;含敢於創造的意味,屬褒詞。後此詞多指本無其事,憑空造作,含貶義。
成效如何?這個行為有時會「站錯重點」,致使出現不合理甚或啼笑皆非的狀況。有AI模型承認當中產生的誤差約三成(已有註明推理結果可能存在偏差)。從嚴謹的角度,這個數字難以接受,不過筆者認為這種性質的能力會隨着時間的推移而得以大大改善;現階段用戶只需「慎用」所提供的答案便可以了。
有AI模型同時也會在網上「實時檢索」。須知道互聯網上的資料,尤其粵語語料,就算排在檢索中的前列位置,亦絕不保證尋得正確答案或事實,皆因位置的高低取決於出現頻率——如最多人說的,無論是真是偽,都會出現在搜尋的前列位置。若然AI具備「驗證」能力——能在眾多說法中作出取捨,那就好辦事,不幸的是AI暫時缺乏這個能力。
要做到能提供可靠的答案予用戶,現在可做的還是有的。建立一個由「粵語語言專家」牽頭的團隊,把現有語料庫中的資料重新審視,以期去蕪存菁以及最重要的補之不足;此舉大大降低對語料庫中所欠缺的作出不大可靠推理的風險。話說回來,如何核實或界定這類「粵語語言專家」的身份以及保證所提供的語料絕對可靠呢?
有AI專家指出絕大部分基於互聯網上的資源數據,訓練出來的「語言層面」智能,不足以進入真實處境以解决所有問題。在市場競爭激烈下,各家AI均有提升輸出品質的優化機制,高可靠性答案的生成指日可期。
筆者會在隨後幾期透過查詢個案,帶領讀者窺探一下AI現階段在中文範疇上的推理能力,繼而作出驗證。
