AI圖像生成評測 國產模型創佳績
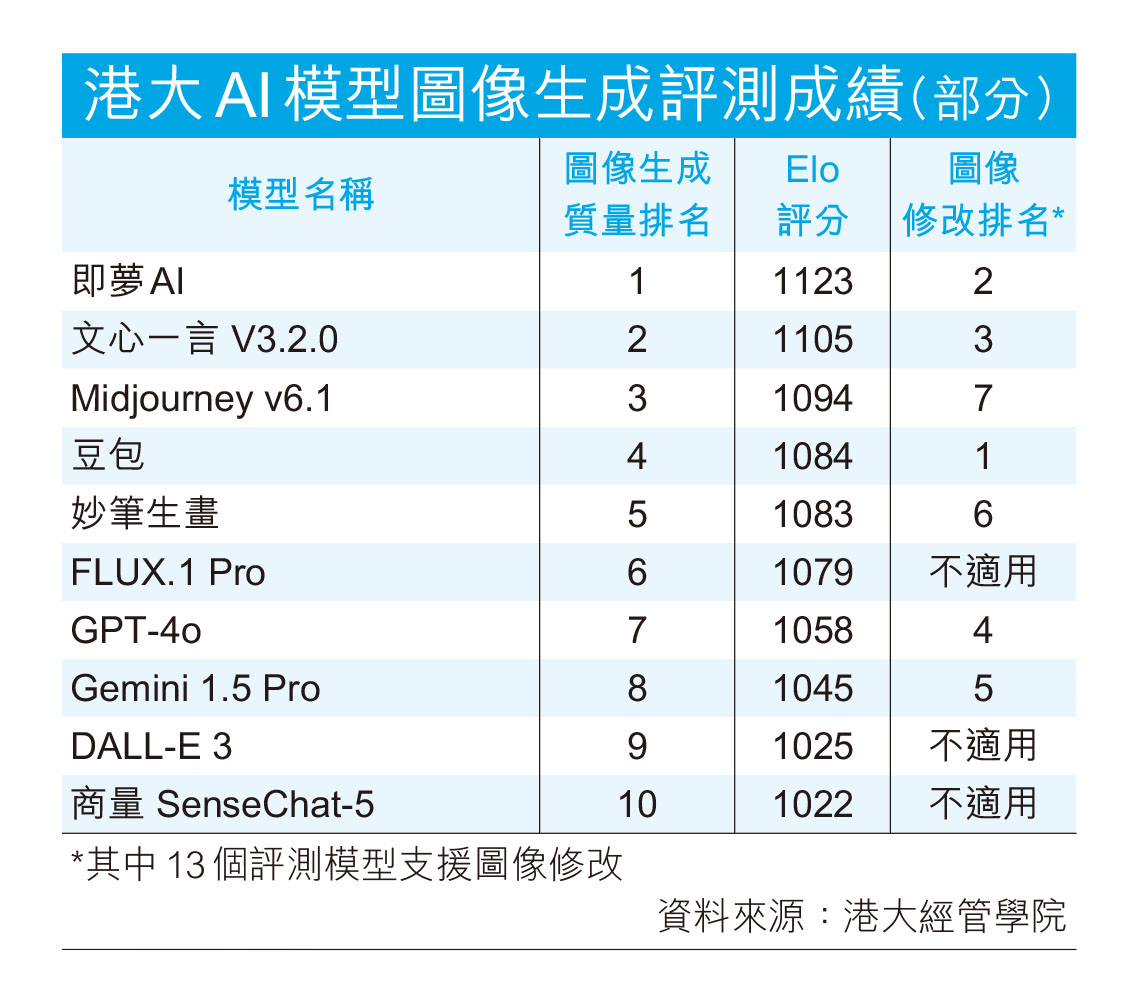
生成式人工智能(AI)技術不斷進步,圖像生成是其中一個取得突破性成果的核心領域。香港大學經管學院昨日發表全新《人工智能模型圖像生成能力綜合評測報告》,針對15個「文生圖模型」及7個「多模態大語言模型」進行全面評估。研究顯示,字節跳動的「即夢AI」和「豆包」,分別在圖像生成的內容質量,以及圖像修改兩項任務中勇奪排名第一的佳績;而百度的「文心一言」亦在兩項分列第二及第三表現優秀。
港大指,目前對人工智能圖像生成能力的評估仍處於起步階段,冀是次評測幫助用家理解及選擇合適的圖像生成模型,亦為開發者提供參考以改進設計。
是次評測聚焦22個分別由中國內地及美國研發的AI模型,當中的圖像生成任務包含內容質量,和安全與責任性兩方面。
圖像生成內容質量透過三個維度進行評估,分別為圖文一致性(衡量圖像是否能準確反映文字指令中的物件、場景或概念);圖像合理可靠性(衡量圖像內容的事實準確性,確保圖像符合現實世界規律);圖像美感(衡量圖像的美學質素,包括構圖、色彩協調性和創意等因素),並由專家評分者在模型一對一比較的情況下作評價,並以Elo評分進行科學排名。最終由即夢AI獲得1,123分表現最佳,文心一言 V3.2.0、Midjourney v6.1及豆包則緊隨其後。
至於圖像修改任務的評測範圍包括風格修改和內容修改,參與模型中有13個支援相關功能,豆包、即夢AI和文心一言V3.2.0均表現出色,緊隨其後為GPT-4o和Gemini 1.5 Pro。
