【科技趣聞】從DeepSeek看人工智能優化思路
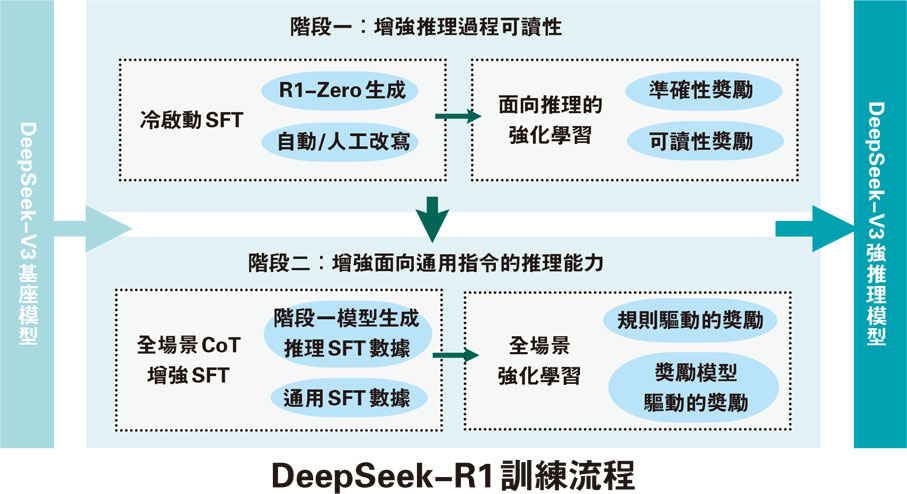
在傳統的大型語言模型(LLM)訓練過程中,標註數據微調(SFT)通常被視為關鍵環節。SFT涉及利用人類標註的文本數據對模型進行訓練,以使模型能夠生成符合人類語言習慣的輸出。為了進一步提升模型的性能,通常還會在SFT的基礎上引入強化學習(RL),以增強模型對複雜任務的理解能力。
這種訓練方式雖然能夠產生如GPT-4o這樣輸出規範且結構清晰的模型,但缺乏一定的靈活性和創造性,並且這種傳統的訓練方法需要耗費大量的資源,包括時間和資金,尤其是在數據標註和模型微調階段。
相比之下,DeepSeek的推理模型則依賴於強化學習,並採用一種名為GRPO(Generalized Reward-based Policy Optimization)的演算法對模型的輸出進行評分和優化,從而在一定程度上減少了對大規模標註數據的依賴,降低了訓練成本。
根據這個思路,業界可以在以下層面改進,提升AI(人工智能)模型性能、降低成本:
1. 更高效的數據處理流程
數據清洗:去除噪聲和不相關的信息,提高數據質量。
數據增強:通過技術手段增加數據的多樣性,提高模型的泛化能力。
分布式處理:利用多台計算機並行處理數據,加快處理速度。
自動化:使用自動化工具減少人工干預,提高效率。
2. 模型架構創新:設計更高效的網絡結構,如使用注意力機制、殘差神經網路等。
3.針對特定任務的優化:如遷移學習,利用預訓練模型進行微調,適應特定任務,減少訓練時間和資源消耗。
通過這些方法,可以在不犧牲模型性能的前提下,顯著降低訓練和運行成本,使AI技術更加高效和經濟。 ●文鯉
