一點靈犀/DeepSeek牽動AI產業價值重估\李靈修
春節期間,最熱話題當屬DeepSeek,彷彿憑一己之力縮短了中美AI技術差距。而從另一層面來看,DeepSeek的成功也意味着開源大模型勝利,為用戶提供的免費服務質量足以比肩閉源大模型。對於後者高昂的估值水平來講,無疑是一個巨大的威脅。
昨日(31日)據美國媒體報道,OpenAI正在就新一輪融資進行初步談判,公司估值有望達到3000億美元。時值「DeepSeek風暴」肆虐美股之際,OpenAI的市場號召力是否受到影響,值得認真觀察。
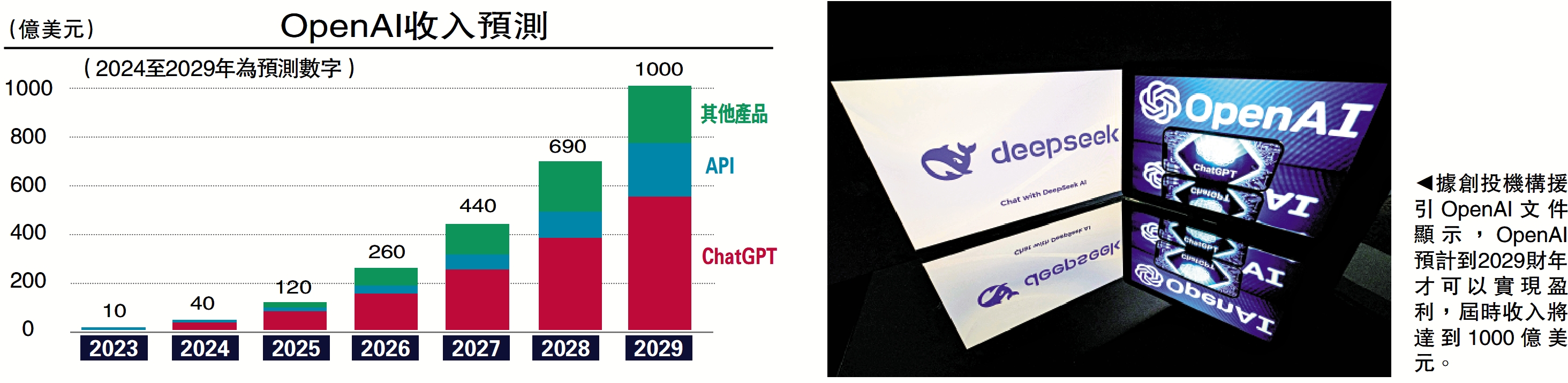
OpenAI上一輪融資發生在2024年10月,彼時估值達到1570億美元。據創投機構援引OpenAI文件顯示,該公司預計到2029財年才可以實現盈利,屆時收入將達到1000億美元。其中,ChatGPT收入為500億美元,API(應用程序編程接口)銷售與新產品項目將各自產生250億美元的收入(見配圖)。
拆穿美科企估值泡沫
然而,與1月20日DeepSeek發布的R1推理模型相比較,在多個邏輯任務(包括數學和編程)的表現R1與OpenAI-o1旗鼓相當。基本上可以說,R1免費提供了o1收費服務。考慮到英偉達市值在美股遭遇到的打擊,OpenAI在一級市場經歷的挫折只會更大。
在舊有觀念中,以ChatGPT、Claude為代表的閉源大模型一直被視為行業標桿。而DeepSeek、Llama等開源大模型的技術水平通常被認為要落後幾個月至一年不等。但2024年以來,AI產業格局確實出現了較大變化。筆者於去年12月30日曾撰文《經營架構調整 OpenAI變身「CloseAI」》指出,「在Scaling Law(規模效應)即將失效的大背景下,OpenAI面臨着被追趕者超越的風險。海外市場方面,公司遭遇到Google新推出的大模型Gemini 2.0狙擊,在中國也出現了像DeepSeek這樣的強勁對手。」
所謂開源大模型,是指大語言模型的源代碼完全公開的,外界可以免費獲取、查看、複製和修改。相關數據也常以開放數據集形式共享,便於開發者使用、擴充和改進。閉源大模型的源代碼則嚴格保密,不對外公開,用戶只能使用其提供的功能接口(API),無法了解內部算法和實現細節。數據通常也由開發公司或組織私有,不對外共享。
迫於輿論形勢與融資壓力,OpenAI對DeepSeek的態度也出現了曖昧的轉變。最初時OpenAI首席執行官Sam Altman還表示,DeepSeek-R1是一款令人印象深刻的模型,OpenAI未來會推出更好的模型。但近日OpenAI官方又稱,發現有證據表明DeepSeek使用OpenAI的專有模型來訓練自己的模型(業內稱之為「蒸餾」),並暗示這可能違反了OpenAI的服務條款。
按照OpenAI的服務條款規定,用戶可以使用OpenAI的API輸出接口將其AI技術與自己的應用程序相結合,但禁止用戶「使用其輸出來開發與OpenAI競爭的模型」。但事實上,「蒸餾」數據在開源大模型領域相當普遍,因為開源AI面向公眾免費開放、而非盈利性商用,不符合條款中「與OpenAI競爭」的定義。
開源AI難被封殺
至於美國政府「封殺」DeepSeek的可能性,很難重現TikTok事件的軌跡。蓋因開源大模型自帶「反封鎖」屬性,其代碼與數據分散在全球各地的開發者手中。即使針對某個平台或地區進行封殺,開發者仍可通過其他渠道獲取和分享代碼,難以實現全面封鎖。
